
Phil Mitchell is a senior mobile engineer with a deep passion for learning in its many forms.
Updated Feb 14, 2020
We live in a time when computers are beating humans at really hard tasks—tasks that until recently seemed utterly beyond machines. Games like Chess and Go are now dominated by machines at the highest levels. Classifying images, detecting and recognizing faces, and medical image diagnostics all are done at or above human performance levels by machines.
Deep Learning is a superpower. With it you can make a computer see, synthesize novel art, translate languages, render a medical diagnosis, or build pieces of a car that can drive itself. – Andrew Ng (Stanford, Google, deeplearning.ai)
The reason for this surge in machine performance comes down to one technology: machine learning (ML); specifically, the branch of ML known as “deep learning”. Deep learning has already been so game-changing that Google’s Pete Warden says:
“[I]n ten years I predict most software jobs won’t involve programming.”
He means that they won’t involve traditional programming; instead, developers will be applying deep learning to solving problems.
Warden is a tech lead at TensorFlow (Google’s ML platform), so he can be forgiven a little hype. At GenUI, we have a slightly different take: in the coming years, we believe, many if not most software projects will use some form of machine learning as a component.
 What does this mean for you as a developer or a project manager?
What does this mean for you as a developer or a project manager?It means that machine learning has got to be in your toolbox. It’s not optional anymore.
But before you panic, understand that the tools of ML are becoming more accessible every year. It’s no longer necessary to have an advanced degree in data science to make use of machine learning.
The analogy we like to give is with databases. Every seasoned developer knows about databases, both SQL and NoSQL, and knows enough about them to use them effectively in typical projects. Yes, there’s a subset of projects, of such complexity or scale, where average database knowledge is not enough. In those cases, expert knowledge of things like performance tuning and database distribution strategies is essential; but for many (or even most) applications, it’s superfluous. Vanilla SQLite or PostgreSQL works just fine.
The same is going to be true of machine learning. As ML tools become ever easier to use, and pre-trained neural nets become available for an ever-growing set of domains, it’s going to become normal for a developer to reach for a deep learning network to solve problems. There will be some situations where you need a deep learning expert; but for day-to-day practice, average knowledge will be just fine. Let’s unpack this.
What problems are we going to be solving with neural nets?Neural nets shine when two conditions are met: (1) solving a problem with code is (really) hard; and (2) you have ample data that exemplifies the solution. You can think of a neural net as an engine that crunches examples and learns patterns.
A typical application is image classification. The annual ImageNet challenge requires programs to recognize objects in images and assign one of a thousand possible categories. In 2011, 75% correct was the best any machine could do. Then deep learning nets were introduced, and now the average solution submitted to the contest exceeds 95% accuracy, well above human performance.
What kinds of skills will the “average” developer need?Recognize a problem that’s a good fit for ML.
For product owners, project managers, and tech leads, this means that when whiteboarding new projects, the superpowers that deep learning brings can reshape your understanding of what’s possible.
Use an ML model created by someone else.
Repositories of pre-trained neural nets already exist, with off-the-shelf solutions that (for some problems) can be directly applied.
Train and tune your own model, based on a pre-trained model.
For most problems, there won’t be an existing off-the-shelf model. But it will almost always be best to start with a pre-trained model, from a more general dataset, and then fine-tune it to fit your specific domain.
For example, most image recognition models are based on pre-trained models from ImageNet, a dataset of more than 14 million, hand-labeled images divided into over 20,000 classes (like “bicycle”, “strawberry”, “sky”). ImageNet models can take days or even weeks to train, optimizing millions of parameters. But we can think about the early layers of an ImageNet model as having learned very general image recognition skills: edge detection, angle detection, textures, gradients, etc. These skills transfer very well to more specific image recognition problems.
So if we wanted to build an image recognizer for, say, cars, it wouldn’t make sense to start fresh and have it reinvent all that knowledge about edges, angles, etc. Instead, we’d start with an ImageNet model and fine-tune it with lots of car images.
Train and tune your own model from scratch.
Not fundamentally different from #3.
Research and design new neural net architectures.
For “average” devs won’t normally be necessary.
It’s not obvious from this list, but a large part of the training and tuning stage is ad hoc “data engineering”: cleaning, transforming, and augmenting the dataset. Developers have home-field advantage here; it’s already part of our everyday toolkit.
Case studyAs a case study, I recently took a deep dive into machine learning myself. I’m a senior mobile developer at GenUI, with no background at all in ML. I spent a few weeks working through the Fastai courses (“Machine learning for coders” and “Deep learning for coders, part 1”) and then I picked a Kaggle problem to really sink my teeth into — Humpback whale identification. Essentially, face recognition but for whale flukes.
To make it more like real life—where your ML problem isn’t on Kaggle—I didn’t crib off any Kaggle notebooks.
However, most challenges on Kaggle are hard—otherwise, they wouldn’t be on there—and this one’s no exception. I did eventually simplify the problem in one key way:
The original dataset has 25,361 images for 5,004 known whales and 9,664 unidentified whales. Many of the known whales in the dataset are represented by only one or a few images. This requires a different approach than any that I’ve learned yet. Instead, I trained my model only on known whales with at least 5 images. With that limitation, I then was able to eventually get to 95% accuracy (with all testing done on a holdout set).
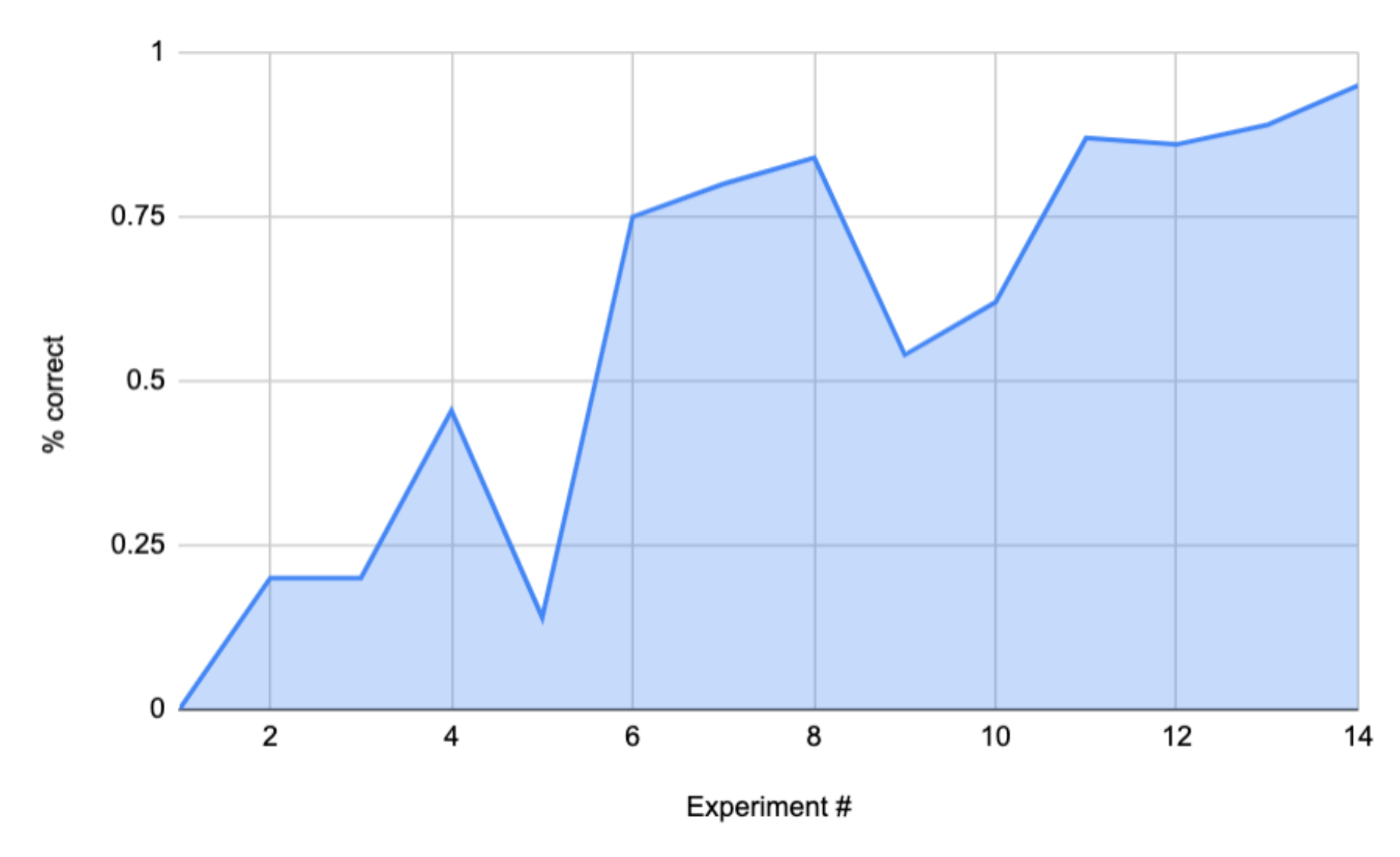
Getting this result required a lot of experimentation and my software chops came in handy. I used ImageMagick to bulk up the dataset even more (adding ten transformed images for every one in the original set). I filtered unknown whales out of the training set. I tweaked Fastai’s resizing strategy and hyperparameters like learning rate and weight decay.
The final result: 95% accuracy on new photos of known whales; or 90% accuracy when the test set includes unknown whales as well. For many applications, that’s good enough.
Now if I had a dev on my team who’d only been working with databases for a few weeks, I wouldn’t expect the world from them. But I’d have every reason to believe that over time, their skill would grow and I’d know that databases would become an invaluable part of their problem-solving toolkit. And I feel precisely the same about now having machine learning in my toolkit.
How to learn machine learningThere’s an abundance of traditional textbooks and courses for machine learning, but I’m going to make an opinionated recommendation: don’t start with a traditional course. To use our database analogy again: if you were just starting out to learn about databases, I wouldn’t have you start with a database theory course where you learned about Boyce-Codd normal forms.
Instead, I’d suggest you take a pragmatic approach, getting your hands dirty right away while getting some guidance about real-world best practices. Fortunately, there’s a growing number of courses that take exactly this approach to ML:
In addition, Kaggle is a tremendous resource. Kaggle is famous as an online data science competition site (eg., Zillow recently sponsored a $1M prize to improve their home pricing model). But what many people don’t know is that it’s also a rich community in which data scientists practice their craft and share techniques. Most competitions have numerous shared notebooks that are a gold mine of practical techniques and advice for learners.
Can we help you apply these ideas on your project? Send us a message! You'll get to talk with our awesome delivery team on your very first call.
 Github
Github
 LinkedIn
LinkedIn